Deadlocks: What would Feynman do?
When confronted with a difficult situation, I often ask myself "What would Feynman do?"
And I know that Richard Feynman, apart from being a brilliant theoretical physicist, gifted lecturer, writer, problem solver, great mind of our age, and all-round wise-guy, was also a bongo player. I don't personally own a set of bongos, but i do have a large swiss ball -- so i took to sitting on a computer chair, with the swiss ball between my knees, beating out a funky congo rhythm using two heavy winter socks as drum sticks. Just Like Feynman.
The problem at hand was deadlocking. Boom ba-da-boom. One little deadlock can ruin your whole highly-concurrent service-oriented-architecture. Boom ba-da-boom.
Deadlocks are easy to fix once you know the cause and you have the solution and it's all wrapped up and you're looking back on it later, preferably with a Singapore Sling in one hand, and an elbow propped on a bar. Listening to some groovy jazz. Tapping your foot, and smiling. Oh, there's nothing easier to fix than a deadlock. Once it's fixed.
(continues, with mystery solved)
But prior to that, a deadlock is a crushing, debilitating, nasty, ugly, painful, evil little problem. Out of the box, SQL Server gives you no help at all. The best you get is a message saying 'hey, there was a deadlock, and a particular statement was chosen as the victim'. That's it. Turning to google, I soon found some great articles from Bart Duncan: Deadlock Troubleshooting.
It turns out that you can ask for more information, by turning on particular options ("DBCC TRACEON (1204, -1)" in SQL 2000, or 1222 in SQL 2005). My deadlocking issues were in SQL 2000, so i had to use option 1204 -- and option 1204 gives you a very obfuscated little message, here's what I got:
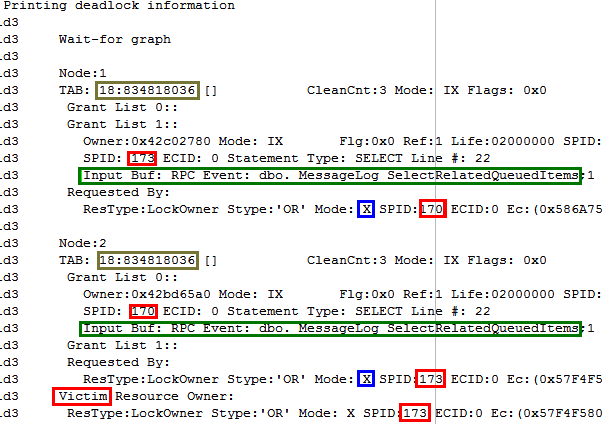
So this turned out to be one of the simpler deadlock scenarios -- where two instances of the same stored procedure are blocking each other. How obfuscated can an error message be!
The highlighted parts of the image tell the story:
- There was a deadlock between process 170 and 173, with 173 chosen as the victim. (this is told by the red highlighting)
- Both 170 and 173 were trying to execute line 22 of of the sproc, "MessageLog_SelectedRelatedQueuedItems" (this is the green boxes)
- Both processes already had an "IX" (intent exclusive) lock on the "MessageLog" table (this is explained by "TAB: 18:834818036." see below)
- Both processes wanted to upgrade from an 'intent exclusive' lock to an actual 'eXclusive' lock. But neither process could, because of the IX lock held by the other process.
The most important parts of the message are the hardest parts to find. In particular the 'X' and the 'IX' were crucial here.
First: why does "TAB: 18:834818036." mean 'the message log table'?
Because we look at those two numbers, 18 and 834818036, and we do the following (in query analyzer):
Use master Select * from SysDatabases where ID = 18
this returned a particular database... let's say it was called the "Message_dev" database. I performed the following:
use Message_dev Select * from SysObjects where ID = 834818036
This returned the MessageLog table
So it's the table itself that the lock is requested on, as opposed to an index or a view, for example.
Exclusive Locks... Intent Exclusive Locks... Could you dummy it down a shade?
Look I try not to think about this stuff too much. When everything is working fine, you never have to worry about what kind of locking strategy is being used under the covers. But when deadlocks occur you suddenly want to understand everything at a very fine level of detail.
Rather than try to understand it completely from scratch, I did what every good programmer would do, and googled for an answer. The incredible Itzik Ben-Gan had helped someone with this exact problem before, so I'll quote his description:
"Technically the deadlock happens because each transaction first acquires an Intent Exclusive lock (IX) on the table and keeps it.Typically an IX lock indicates the intent to modify rows at a lower granularity level.
Then the transaction attempts to acquire an Exclusive table lock (X); I believe that it attempts to acquire an X table lock and not go through Intent Update (IU) and Update (U) locks first because you requested to work with a serializable isolation level, and since there's no index, the way to guaranty serializable is to lock the whole table.
An IX lock is compatible with an IX lock, therefore two different transactions can acquire IX locks at the same time. But an X lock is incompatible with an IX lock, so when the timing is such that both transactions managed to acquire IX locks and then ask for an X lock, they're blocking eachother and you have your deadlock.
if you add a TABLOCKX hint, you tell SQL Server that you want to exclusively lock the whole table to begin with, so there was no need for IX locks, hence no deadlocks.
Also, The deadlock doesn't happen in read committed isolation because the transaction requests the following sequence of locks:
1. IX table
2. IU page
3. U row
4. IX page
4. X row
The key in the deadlock prevention here is that U lock is incompatible with U lock (not with previously acquired locks) so one transaction blocks the other as opposed to both blocking eachother.
So a couple of ways around the deadlocks are:
1. Use the hint
2. Use read committed isolation
A third option that I tested that seems to work is to create a clustered index on the other column. I have to start class so I can't check the sequence of lock requests that helps preventing the deadlock... I'll leave it to you... ;-)"
(see, original message here)
Okay -- i followed Ben's advice and I soon got there. I didn't use the table hint he suggested, as locking the entire table seemed like overkill. I was able to change the isolation level to read-committed. After running a lot more load-tests on the server, the deadlock didn't re-occur, so we were happy with the solution.
One thing I'm left wondering -- is there a way that SQL server will tell me what locks were applied for a given query? So I don't have to try and calculate it myself, with the margin for error/incompleteness this entails?
In any case, this was perhaps the second nastiest problem I've dealt with this year, and I thought I ought to record it somehow. Once I understood the problem fully it seemed strange that I don't hit this kind of problem more often. The fact that it only occurs under highly concurrent situations might be the only saving grace.
Anyway, time to get back to playing those drums. Bring it on Feynman.
Next → ← PreviousMy book "Choose Your First Product" is available now.
It gives you 4 easy steps to find and validate a humble product idea.