TimeSnapper 2.3: Extract Text Using Optical Character Recognition

After much effort, we've now released the next incarnation of TimeSnapper -- version 2.3.
(Wondering what TimeSnapper is? Overview here)
The killer feature this time around is Optical Character Recognition. You can now select text straight out of the images you capture.
We've been keen to include this feature since day 1, and finally it's in!
Here's some pictures of it in action...
While viewing a screenshot taken by TimeSnapper -- right click and choose "Extract Text..."
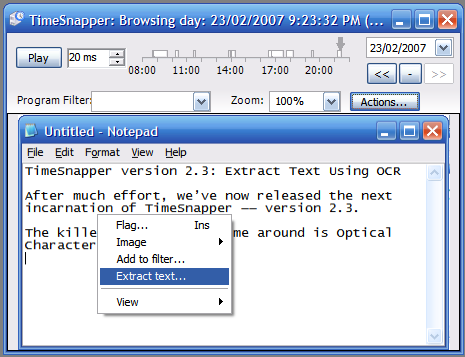
The image is quickly analyzed for text. Highlight the words you're interested in...
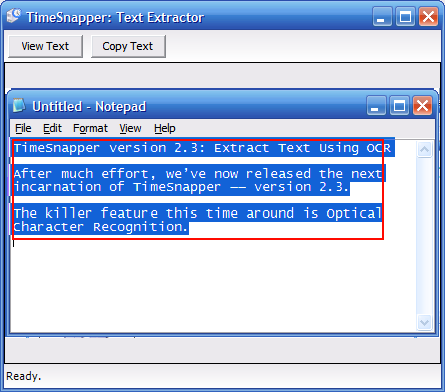
Press view text... and the extracted words are shown in a "Notepad-like" window.
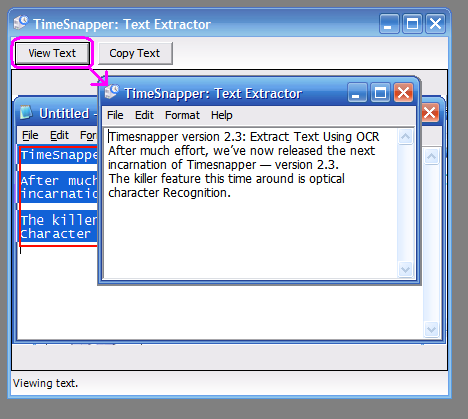
(Or press Copy text to move the text onto the clipboard).
For example, here's the text I extracted in the screenshots above:
TimeSnapper version 2.3: Extract Text Using OCR After much effort, we've now released the next incarnation of TimeSnapper -- version 2.3. The killer feature this time around is Optical Character Recognition.
Now we're really getting close to one of our original goals:
Never Lose Your Work Again
This feature is already getting a serious workout on my home computer. So many of the programs we use every day do not have any kind of auto-save feature. The Text Extractor in TimeSnapper completely overcomes that problem!
No more slaving over an email for an hour, only to close the browser and lose your work. There's no excuse now.
But also -- we should add that OCR technology is not magic. It doesn't get every letter right, and it can get confused by background images, and other 'artefacts' in the image. If the image you've captured is low fidelity (e.g. jpeg or gif) you're also going to get a lower quality OCR experience. Personally I use png at 100% quality, and I'm happy with the results.
And the credit goes to...
The OCR functionality relies on Microsoft Office Document Imaging -- which is installed with Office 2003 and Office 2007. They in turn licensed their OCR capabilities from TextBridge. So 'Extract Text...' will only work if you've got Office 2003 or Office 2007.
We probably would never have known that these features were available if it weren't for Martin Welker's excellent code project article "OCR with Microsoft Office".
And also, Jon Galloway has been evangelising TimeSnapper, and writing about OCR -- so he gets an honourable mention.
The Unstoppable Feedback Machine That Never Sleeps
Another very helpful factor with this release was the incredible stream of feedback from Adam Cogan. (Adam's a Microsoft Regional director in Australia, and he runs Superior Software for Windows). Adam is a FEEDBACK MACHINE! Nights, weekends, early mornings, emails, IM, phone calls... he's relentless.. unstoppable... i'm just glad he harnesses his energy for good instead of evil.
As a result of his feedback there are numerous improvements to usability, consistency, attention to detail, quality. We haven't yet done everything he's asked for (we're only human) but we're a good part of the way there.
Also, we get a steady stream of emails from people using TimeSnapper who either give us suggestions or make us aware of bugs. In addition to the forum, we're pretty well equipped when it comes to feedback.
But More Feedback is still needed
But of course we still want more feedback. Does the text extraction work for you? Do you need something more from it? Anything that confuses, annoys or delights you with TimeSnapper?
Keep us informed!
Next → ← PreviousMy book "Choose Your First Product" is available now.
It gives you 4 easy steps to find and validate a humble product idea.