XPLT: eXtensible Parser Language Transformations
A general language for transforming raw text files from one format (and/or encoding) to another. The input files do not have to be XML documents. The output files do not have to be XML documents (though often they will be).
When you dream of software regularly, it's a bit of a worry. Anyhow, this is an idea I had while mowing the lawn today. I think it could really speed things up interconnecting legacy systems with the XML-aware world. What do you think?
XPLT borrows from XSLT and Regular Expressions (RE), but also provides a more human-readable style of Pattern-Matching, encapsulated within the Pattern element. Patterns are combined with templates and flow control semantics, that allow for very flexible document transformations.
XPL Transformers could be written on any platform, for any technology. Collections of specific and re-usable XPL documents for converting between any two text-formats could be shared and distributed.
Underlying principles of XPL
- Human Readable
- Not concerned with Terseness
- Platform Independent
- Transport Indepedent
- XPL documents are valid XML documents
How is it used?
Here are some typical scenarios for which XPLT is useful.
- EDI documents, containing data in fixed-width fields, need to be converted to XML for transmission to a web service
- A legacy system produces CSV documents. They can be converted to XML using XPLT.
- A trading partner produces XML documents that are not always well-formed. They can be 'pre-processed' with XPLT to produce well-formed XML.
- An RSS aggregator receives some documents that are in an obscure format. They can be transformed to valid RSS using XPLT
- A HTML doc needs to be parsed to retrieve certain values.
- VB.net code needs to be changed into C#
- HTML code includes embedded font tags. It needs to be altered to use CSS.
- Wiki Text needs to be converted to xHTML.
- A regular expression needs to be converted into a human-readable explanation
These problems can be solved by writing custom parsers, or, at best, through clever use of Regular Expressions.
Maintenance of such code can prove remarkably expensive. Why?
- System boundaries are *always* in a state of flux.
- Custom parsing is notoriously buggy -- even if it runs error-free for six months, you know there is a chance that an unexpected character combination could upset it.
- Regular Expressions are deliberately terse. This limits the number of developers who take the time to master them.
- The platform and underlying technology of a system boundary can change. Any platform or technology dependent code then needs to be rewritten completely.
Features of the Language
The main features of the language are:
- the Pattern
- flow control
- the replace construct
- the template
From XSLT it borrows elements used for these constructs:
- If/else statements
- Choose statements
- for-each
- Sort
In XSLT, the 'Match' and 'Select' attributes reference an Xpath expression. In XPLT the equivalent attributes reference a named Pattern element.
The Pattern Element
A pattern element serves a purpose analogous with a Regular Expression (RE). It can, infact, be simply a RE, for example:
<pattern name="email" RE:match="(\w[-._\w]*\w@\w[-._\w]*\w\.\w{2,3})" />
[Thanks to Darren Neimke for the RE example, taken from RegExLib.]
Any such pattern can also be expanded using the far more verbose pattern semantics of XPLT.
<pattern name="email" >
<all> <-- inside an 'all' element,
all rules must be applied --/>
<chargroup occurs=1>
<char class='word'/>
</chargroup >
<chargroup occursatleast=0>
<any> <-- inside an 'any' element,
only 1 rule must be applied --/>
<char class='word'/>
<char value='-' />
<char value='.' />
<char value='_' />
</any>
</chargroup >
<chargroup occurs=1>
<char class='word'/>
</chargroup >
<chargroup occurs=1>
<char value='@'/>
</chargroup >
<chargroup occurs=1>
<char class='word'/>
</chargroup >
<chargroup occursatleast=0>
<any>
<char class='word'/>
<char value='-' />
<char value='.' />
<char value='_' />
</any>
</chargroup >
<chargroup occurs=1>
<char class='word'/>
</chargroup >
<chargroup occurs=1>
<char value='.'/>
</chargroup >
<chargroup occursatleast=2 occursatmost=3>
<char class='word'/>
</chargroup >
</all>
</pattern>
Okay - the names Char, Chargroup etc, are pretty ugly. But I've just invented them now. The structure of those pieces could be altered and improved, I am sure. Just food for thought. Rather than
<chargroup occurs=1> <char class='word'/> </chargroup >
<char class='word' length='1'/>
And Rather than
<chargroup occursatleast=0> <any> <char class='A'/> <char value='B' /> <char value='C' /> <char value='D' /> </any> </chargroup >
You could just say:
<chargroup occursatleast=0> <any>ABCD</any> </chargroup >
I guess you would also have 'greedy' and/or 'non-greedy' attributes.
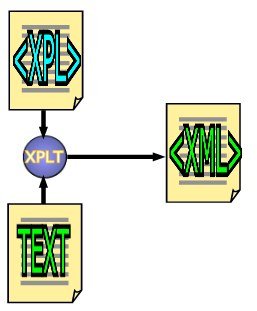
Here's the original picture I came up with -- the complete loop converting proprietary text into XML by using XPLT. Then converting the XML back into properietary text, by way of XSLT.

I'm damn tired now -- so i'll stop there. Cheers!
Disambiguation
XPL is not any of the following:
- A language for writing compilers.
- A scripting language for the Note Bene word processor.
- A MIDI programming language for Amiga.
- A language called eXtensible Programming Language.
- A Pascal-like language named XPL0.
My book "Choose Your First Product" is available now.
It gives you 4 easy steps to find and validate a humble product idea.