My point is that while XML is similar to a mark-up language, it is in fact far more brutal than one. It oversteps the line and is, instead, an exclusive document formatting language. In the process it has lost a lot of the benefits of mark-up.
The idea of mark-up, is elegant, light and beautiful when compared to these heavy 'document formatting' techniques we've taken on instead.
Consider a piece of text, that is not marked up:
Take your god damn hands offa her.
If we want to "mark it up" we can use special codes of some sort to impose a second meaning on it:
Maybe we'd use slash characters:
Take your //god damn// hands offa her.
Or in gaXml we might say:
Take your <em/god damn/> hands offa her.
But to mark this text up using xml, we have to be a lot more brutal:
<?xml version="1.0" >
<quote>
Take your <em>god damn</em> hands offa her.
</quote>
See in xml you can't simply mark up the parts of text that we wish to give a special meaning to. We must give a special meaning to every single part of the document. Even if you don't know anything special about the rest of the document. Weird isn't it?
For that reason, XML can never just adding marks/meaning to portions of text: instead it becomes The One True Meaning Of The Document.
So, rather than the markup being placed inside the text, the text is dragged, kicking and screaming into the markup.
Don't get me wrong: I do love XML. I'm just starting to hallucinate about the world beyond it.
The great benefit of XML is that it's easy to write an xml parser, because xml documents are so very machine-readable.
But by using such an all-encompassing format, we destroy any machine-readability that the document might otherwise have had.
For example, a C# document is perfectly machine readable. (Assuming the machine has a C# compiler). Ditto a python document, a ruby document, or a CSS file.
But when we mark up that document using XML, we have to use an all or nothing approach.
Either we embed the C# file inside an XML document, and it can no longer be compiled by a C# compiler.
Or we embed 'xml-like' comments in the C# document, and (since they're not quite XML) they can't be read by any XML parser on the planet. We need a specific "C# with embedded XMl-like stuff" pre-parser to do the job for us. It doesn't matter how many XML parsers there are, cause there aren't a lot of 'pre-parsers' available.
Life After Xml
I'd like to see a simpler mark-up language, that allows for more flexible documents. (They'd still have strict heirarchy and well-formedness, like XML).
I've tinkered with names for it... XXML, X2ML 2XML, iXML,... for this blog entry i'll stick with the name iXml, though i'm not at all attached to it.
XML would be just a sub set of iXML. In other words we'd need to rewrite the genealogy of XML.
Instead of following this old blood line:
<sgml>
<html />
<xml>
<xsl />
{etc.}
</xml>
</sgml>
(i.e. xml is a child of sgml, and xsl is a child of xml, etc...)
We'd change it to be:
<iXml>
<xml>
<xsl />
</xml>
<css />
<c />
<c# />
<ruby />
{etc.}
</iXml>
(i.e. xml is a child of iXml. Css grammar is also a descendent of iXml... so are many other formal grammars, provided they are strict....)
The idea of iXml is that it doesn't need to ruin a document's existing machine-readability (or human readability for that matter).
Anonymous Structure
Thanks to thinking about Linq, anonymous types and some other stuff, i've thought of something else that XML lacks, because of its verbosity. This could never be pushed into XML, but could fit into iXml nicely.
Consider this nice piece of CSV:
1,2,3,4
How would that look in XML?
<?xml version="1.0"?>
<Numbers>
<Number>1</Number>
<Number>2</Number>
<Number>3</Number>
<Number>4</Number>
</Numbers>
Now the official excuse for this sort of monstrosity goes back to the XML spec, where they say:
Terseness in XML is of minimal importance.
But the problems with the above XML example, are not just it's verbosity, but that it forces us to invent meta-data. The list in its original form didn't impose any kind of type, or name upon the data.
So here's a different feature of iXml: it allows for anonymous "structure-only" markup!
<>
<>1</>
<>2</>
<>3</>
<>4</>
</>
So in the above case we can see that the data values 1, 2, 3 and 4 are all siblings. We don't need to invent an element name for them, if all we want to impose on them is a heirarchical set of relationships.
(I guess a rule would also be needed to define an empty anonymous element, in the example above [since '</>' is already taken to mean an empty closing element. I figure an empty anon element would be written: '< />'. Can't think what you'd use it for... a place holder of sorts i guess.)
Polyglotics
A polyglot is a person who speaks more than one language. In programming, a polyglot is a document that is valid in more than one language.
It sounds like a dangerous and bad thing. It sounds like a maintenance nightmare.
in fact, polyglotics is already all around us.
A static html document can be polyglotic: combining html and css in a single document.
A dynamic html file will combine three different syntaxes, each delimited in different ways: html, javascript and css.
A worst case scenario document might combine: html, javascript, css, asp, vba, embedded sql, regular expressions, comma separated values, and embedded xml all in the one document!
It's a pity that XML, because of it's over-reaching design, doesn't allow for polyglotics.
An iXml parser would be able to separate those threads out, treat them separately, and even allow different people to work on each of those sections simulataneously...
Alright, i've blurted out too much about my inner-inklings now. Finally here's a rewrite of the designs goals of XML, appropriated for iXml.
- iXML shall be straightforwardly usable over the Internet. Like duh.
- iXML shall support WAY MORE applications than XML.
XML shall be compatible with SGML. (screw sgml!)- It shall be fairly easy to write programs which process documents containing iXML markup.
[Not as easy as XML... but who needs 1,000,000 parsers? A dozen good ones would suffice.]
- The number of optional features in iXML will be much higher than in XML... deal with it.
- documents containing iXML markup should be WAY MORE human-legible and
reasonably clear than those dodgy XML docs!
- The iXml design should be prepared quickly.
- The design of iXml shall be sorta formal and sorta concise.
- iXml marking shall be easier to create than XML with it's dodgy "let's take over the entire document" philosophy.
- Terseness in iXml markup is of relative importance.
Tim Bray, I await your reply. ;-)

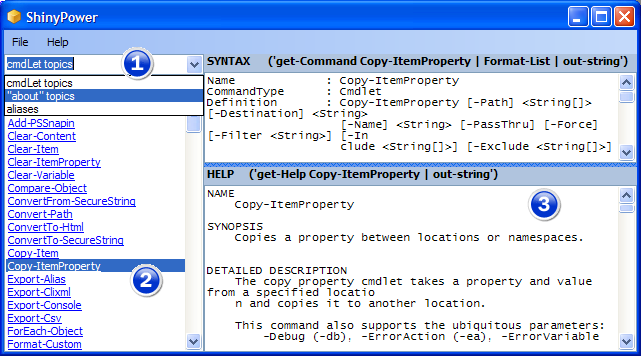
 Download ShinyPower (for RC1) (and then unzip) from here.
Download ShinyPower (for RC1) (and then unzip) from here.