XML for example has this... general purpose issue.
they (whoever they are...) they say -- "XML is so extensible, you can use it everywhere."
But that really means nothing at all. (I'm trying not to... ... y'know... mention lisp...)
XML is so extensible that knowing xml means nothing -- you can know everything about xml but know nothing about how it's used to solve a given problem. Knowing XML doesn't mean you can write a Nant script. It doesn't mean you can write a stylesheet in XSL. It doesn't mean you can process BPEL4XML.
And just say you do use xml for a specific purpose. XSLT for example. You quickly find that XML as a programming language sucks.
XML is very versatile because it can contain any element you think of. It can do all sorts of wonderful backflips. But no matter what new things it does, it doesn't stop being XML:
it's too verbose to be written by any happy pair of hands. it doesn't lend itself to common programming idioms (for example, you can't really express "If/Else" in XSL -- instead you have to write something more akin to a 'switch' (actually called a 'choose' here) whenever you want a straightforward if/else. this is "shovel-in-the-face-ugly" programming at its finest.)
An Elephant Is The Only Mammal That Can't Jump
Back to the general point: General purpose languages say nothing when they try to say everything.
"Do I know the C programming language? Well Let me put it this way, buddy! I know the entire English alphabet, all the punctuation characters, plus all ten digits... and C is written entirely in the English alphabet, a few punctuation characters, and a couple of digits.... so yes indeed I do know C, mister. I know a heck of a lot more than that. I've used many of those characters my entire professional typing career."
Consider HTML. Initially it was used for both the structure and display of information. Those are two very small, and closely related domains.
But even this was soon found to be very inefficient. So a second, more specific mini-language -- CSS -- was created to handle the presentation aspect.
This is a trend we see over and over -- little languages are created to handle specific little problems. Any big solution will tend to contain a lot of these "little languages".
Even XSL includes an extra little language -- XPath. (While I dislike XSL, I still have a kind of sweet spot for XPath).
A big solution might contain HTML, CSS, XML, SQL, Xpath, Regular Expressions and a number of other little languages. And on a managerial level it might seem messy, ugly, disorganised... but no it's beautiful, efficient, stylish, in a kind of eclectic bohemian way.
And the next point in this "Midnight Friday Rant" is this:
languages are themselves composed of little languages
with other little languages bolted on the side...
...and programs written in those languages:
create extra little languages on top
of the little languages underneath
i'll go through some of those claims, a little more slowly.
languages are themselves composed of little languages...
You remember from the hazy hungover university days that language grammars are defined in EBNF - "The Extended Backus-Naur" Form.
For example, here's a chunk of EBNF defining the if statement in powershell.
<ifStatementRule> =
'if' '(' <pipelineRule> ')' <statementBlockRule> [
'elseif' '(' <pipelineRule> ')' <statementBlockRule> ]*
[ 'else' <statementBlockRule> ]{0|1}
Notice how this rule is built on top of other rules -- the statementBlockRule, the pipelineRule, and a sprinkling of keywords.
Language grammar is a conglomeration of 'rules'. And those rules are built of smaller rules. That's what I mean when I say 'languages are themselves composed of little languages'. It's turtles all the way down.
And I find this a pretty intriguing thought because it means that you can alter the language itself by altering any one of the little rules on which it's built -- you can even imagine expanding any one of these rules to become an entire programming language in itself.
C# 3.0 for example introduces a new argument modifier -- 'this'. It's only a little part of the written language -- but it gives the compiler a hell of a lot of groovy work to do, and it gives the coder a lot of comfortable features, that overcome a lot of the 'execution in the kingdom of nouns' problems that C# suffers.
When you think about these mini languages one by one -- you see opportunities for changes (some good, many bad) and you see the limitations that the language designers imposed on the system. A lot of the potential for clever innovation is beyond our imagination. There's potential here that we can't kid ourselves into believing we can see. (hell, even the wisest language designers get their best inspiration by stealing off others)
Any one of these rules can be expanded into a language of its own. I'm thinking macro languages. I'm thinking meta-programming.
Take this line of C# 2.0 for example:
public class LinkedList<K,T> where K : IComparable<K>,new()
That final clause means the type K must implement IComparable and have a default (parameterless) constructor. This dense little phrase is a mini-language at its most naked. And I wonder why the language designers stopped here, since they'd already gone so far.
A different mini-language that I'm wanting to see in C# is the use of 'pattern matching' -- a fancy terms that means allowing various method overrides to distinguish themselves not just by the types that they accept, but the values too. The sort of overrides we have in C# today distinguish themselves by type: "this over-ride accepts an object while that over-ride accepts a string". "Pattern-matching" is a language feature (used in many functional languages) where different over-ride distinguish themselves by the incoming values they accept: "this over-ride accepts an integer less than 0, while that over-ride accepts an integer greater than or equal to zero". It's a versatile idea that pushes the complexity into a mini-language, where it can be expressed most concisely, rather than leaving it in the mega-general language where it's cumbersome and ugly.
On to the next point:
General Purpose Languages... have... other little languages bolted on the side...
This isn't a re-hashing of the previous point, but an entirely different point altogether.
A general purpose language includes, as part of its core, libraries that implement other, syntactically discreet little languages.
Regular-Fricking-Expressions, for one. A beast of a mini language. A DSL on steroids. If you think your language is better at expressing regular expressions than regular expressions, then hats off to you and I hate your language to bits and pieces. Regular expressions are a world unto themselves, perfectly matching a specific and nasty little knot of problems, and perfectly creating a far nastier little knot of problems, of course.
But look at other mini languages expressed in .net (for example). The string formatting language! The asp.net binding language! Pretty much everything about data access hints at a type-less interpreted mini-language bolted onto the side. (To back up that ambit gambit, here's a quote from Eric Meijer's paper, [PDF!] static typing where possible, dynamic typing when necessary:
"the fact that the datareader
API is �statically� typed is a red herring since the API is a statically typed interpretative layer over an basically untyped API (sic)"
(found thanks to local legend Joel Pobar)
[special note to editor-geeks: there's such bliss in quoting a language master, yet getting to use a 'sic' disclaimer...]
So no matter how sweet a 'general purpose language' like C# may be, it still includes interpretative layers over an other, domain-specific API's, as part of the core framework. This indicates that maybe (big maybe) there is not now, nor ever will be an efficent and self-contained general purpose language.
Learn a dozen languages, fat head. You need them all.
And we implement... extra little languages on top
So the next big issue is that by writing our own programs in a given language, we create new mini languages of our own. Once we've written our Database Access Layers, then a blub programmer can come along and compose their own 'business solution' entirely using our domain-specific terminology of Customer and Order and Address and so on.
In C# you get to define new types -- that's the basic method of extending the language. Those types can be inherited etc, can have specific methods and so on. Operators can be overloaded. A couple of other methods. Plus extensions methods in 3.0. That's about it.
Other languages boast that much language creation can be achieved, essentially (as far as I can tell -- novice, me) because noun, verb, symbol, keyword, bracket and so on can be swapped around -- and thus claim that 'new programming constructs' can be built on top of the underling General Purpose Language
This is where the versatility of our general purpose language really comes into play. This is the area where the lisp advocates begin to salivate and kiss each other in rabid orgies of delight. Sickening stuff. You notice they were pretty quiet during the earlier segments. This is where the versatility of XML comes to the fore.
For example, long ago, people worked out how to turn Lisp into an object oriented programming language by implementing something that came to be known as the Common Lisp Object System on top of common lisp.
There's a neat concept (The Principle of Least Power) raised by our old buddy Tim Berner's Lee (inventor of the intarwebs) who explained that the dumber a language, the more re-usable the data stored in the code itself becomes. A real ability to build languages on top of your languages seems, for now, to be pinned to the underlying languages Parse-ability.
Some languages proudly claim to have the same kind of explicit extensibility as lisp, when all they really allow is 'inventive use of eval and some clever string munging' (hat-tip don) but i digress. While digressed on the eval topic.... i did say last week that:
...i think i can use eval() to make it far more powerful yet.
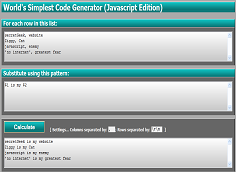
... well i went ahead and used eval to make the world's simplest code generator (javascript edition) far more powerful... no time to explain it now... view source if you need help ;-). Digression over.)
While discussing language over-lays, something I regret here is that while languages boast an ability to pile new language languages on top, there's never an ability to clamp down on the complexity of the underlying languages... I'd love, for example to be able to switch off aspects of certain languages. In Visual Basic, turn off the non shortcutting 'and' and 'or'. Or, In C# for example, (as happens in Spec-sharp) the ability to make reference types non-nullable -- or, as in F#, an inability to move through an if statement without specifying a corresponding else statement. [possibly bogus example -- no comments required]
Balancing all these things, I think the way forward is Javascript.
Kidding. Just tired and keen to send this out. It's almost 1 am, and i've got matt's pre-wedding chug-a-thon tomorrow. Wish me luck and remind me to keep it together.
disclaimer: while i love languages -- i'm still just a language fanboi. i never did the language subject at uni. i never read the dragon book.



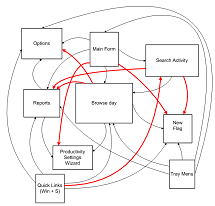
![navigation in timesnapper the day after tomorrow [predicated]](https://secretgeek.net/image/timesnap_spaghetti1_th.PNG)
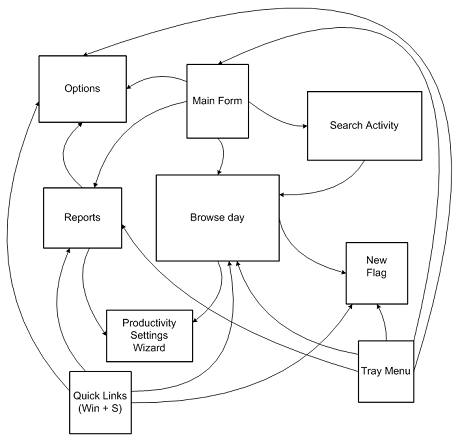
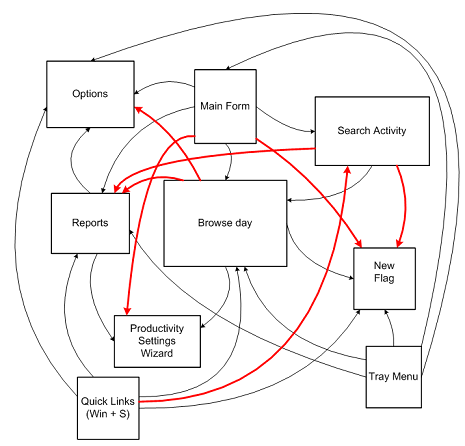
![navigation in timesnapper the day after tomorrow [predicated]](https://secretgeek.net/image/Flying_Spaghetti_Monster_a.JPG)